
Tristan Bunnage | Summer Intern | 18 March 2025
In January 2025, I was offered the opportunity to undertake a four-week internship program alongside Fortian's Managed Security Services (MSS) team. This opportunity appeared at a time when I had veered away from an academic career path in applied mathematics and statistics. Armed with only interest and a pop-science equivalent understanding of the cyber world, I was keen to discover how my skillset could translate to the cyber domain.
The MSS team selected a project which aligned with my background and would provide useful insights to clients. My task was to perform a model-assisted threat hunt to try and detect potential password spray attacks against a client's customer accounts. To do this, I first had to familiarize myself with large datasets containing what seemed like an endless number of logs, then use that data to build a model that can help identify anomalous behaviour.
A password spray is a common credential access technique designed to evade detection. Simply put, an adversary attempts to gain access by trying a commonly used password across multiple accounts. There are a few characteristics that can be assigned to a given password spray:
A password spray may be difficult to detect based on which of the above characteristics the attack inherits. Single source and high frequency sprays tend to be easier to detect, and simple alerting/time series methods can be used to remediate them. Distributed low and slow sprays are much harder to detect, as the attack can occur over multiple months, sometimes years, and blend in with background noise. The key to detecting distributed low and slow sprays is to leverage fields whose distribution is unknown to the attacker. Therefore, they must guess or randomise these values and risk deviating noticeably from the background noise.
Confronted with a large dataset which contained details which I didn't understand, I wasn't entirely sure where to start. Luckily, the MSS team had already created a Jupyter notebook for detecting password sprays targeting staff accounts. The model used is k-means, a simple clustering algorithm that groups similar data points together based on their features. Given its success with staff accounts, my first approach was to adapt this method for customer accounts. That shouldn't be too hard, right?
Wrong.
The customer sign-in dataset had some differences which made using k-means an unsuitable tool for the job. Customers sign in to their accounts from a diverse range of locations, times, and devices. This led to high variance across multiple fields in the dataset. Combined with an order of magnitude more logs that the staff accounts, this made choosing a reasonable number of clusters difficult. Furthermore, the customer logs had fewer features to cluster on. Each sign in was into the same service, there are no onboarded devices, and precise location data was messy, if not missing altogether. I was unable to partition the logs into useful clusters where I could isolate anomalous events.
After multiple attempts, it became clear that k-means wasn't the right tool for this dataset. The high variance in customer logins made clustering ineffective, and the model struggled to identify meaningful anomalies. To overcome these limitations, I decided to try a different approach: DBSCAN.
DBSCAN is another commonly used clustering algorithm which groups together densely packed datapoints and produces a separate partition of isolated outlier points. This has two advantages over k-means: The number of clusters is not fixed, and a set of outliers are naturally determined. I selected relevant user and location data as features, cleaned the data frame, and clustered the data using DBSCAN.
Of roughly 150,000 logs, 800 clusters were found along with a few thousand outliers. From here, the clusters are pruned, filtering out partitions with a high sign-in success rate to obtain a set of suspicious clusters. The outliers are also pruned, removing successful sign-ins from the suspicious set. This is necessary to remove noise but unfortunately carries the risk of dismissing successful malicious attempts.
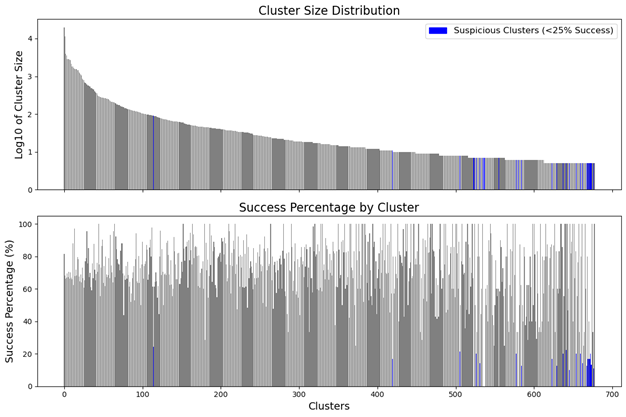
The remaining dataset consists of nicely clustered suspicious sign-in attempts. Analysis of the suspicious clusters reveals almost all of them indicate brute force attacks, however, many were more likely to be customers repeatedly guessing their own password. There was, however, a clear brute forcing attempt detected earlier in the month by the MSS team. The remaining anomalous points consisted of randomised sign-in attempts, isolated from all other points. These are low and slow spray candidates. No evidence of single source sprays or high frequency sprays were found.
While it is a good sign that a brute forcing attempt was found, we unfortunately cannot assess how well the model performed. To do so, we would need a labelled dataset - one where a known attack has occurred, and the specific malicious sign-in attempts have been identified. There may have been a password spray attempt in the used dataset, but we cannot be certain.
In the final few days of my internship, I performed a heuristic test, where I injected 15 login attempt logs with randomised fields within a short period of time into the dataset. Of the 15, 12 attempts were detected and clustered together indicating that distributed attacks could be found. This, however, is still unlikely to have the indicators of a real attack.
While I was not able to properly assess the performance of the model, I can safely assume based on its mechanism that it will detect single-source sprays and high-frequency distributed sprays with some success. It is unlikely that low-and-slow sprays can be detected with certainty, however, the model produces a list of candidates which can be investigated further.
Undertaking this internship has been deeply rewarding. Over the course of four weeks, I had to familiarise myself with cybersecurity and the massive amount of data involved in the field, while determining a model which is sufficient for the task at hand. These challenges increased my confidence, and I am now enabled to develop more complex models further catered to the types of data the MSS team works with.
Working with a team so friendly, passionate, and welcoming has further added to this wonderful experience. I strongly encourage anyone who is interested to apply — your skillset might be more valuable than you think!
Request a consultation with one of our security specialists today or sign up to receive our monthly newsletter via email.
Get in touch Sign up!